Bei der Entwicklung moderner Prozessoren gibt es eine Tendenz zu einer allmählichen Erhöhung der Anzahl der Kerne, was ihre Fähigkeiten beim parallelen Rechnen erhöht. Allerdings gibt es in dieser Hinsicht schon lange GPUs, die den zentralen Recheneinheiten weit überlegen sind. Und diese Fähigkeiten von GPUs wurden von einigen Unternehmen bereits zur Kenntnis genommen. Die ersten Versuche, Grafikbeschleuniger für Off-Target-Computing zu verwenden, wurden seit Ende der 90er Jahre unternommen. Aber erst das Erscheinen von Shadern wurde zum Anstoß für die Entwicklung von absolut neue Technologie, und 2003 erschien das Konzept der GPGPU (General Purpose Graphics Processing Units). Eine wichtige Rolle bei der Entwicklung dieser Initiative spielte BrookGPU, eine spezielle Erweiterung für die Sprache C. Vor dem Aufkommen von BrookGPU konnten Programmierer nur über die Direct3D- oder OpenGL-API mit der GPU arbeiten. Brook ermöglichte es Entwicklern, mit einer vertrauten Umgebung zu arbeiten, und der Compiler selbst implementierte mithilfe spezieller Bibliotheken die Interaktion mit der GPU auf niedriger Ebene.
Ein solcher Fortschritt konnte die Aufmerksamkeit der Marktführer dieser Branche auf sich ziehen - AMD und NVIDIA, die mit der Entwicklung ihrer eigenen begannen Softwareplattformen für nicht-grafisches Computing auf ihren Grafikkarten. Niemand besser als GPU-Entwickler kennt alle Nuancen und Funktionen ihrer Produkte perfekt, was es denselben Unternehmen ermöglicht, so effizient wie möglich zu optimieren Softwarepaket für spezielle Hardwarelösungen. Derzeit entwickelt NVIDIA die CUDA-Plattform (Compute Unified Device Architecture), AMD nennt diese Technologie CTM (Close To Metal) oder AMD Stream Computing. Wir werden uns einige der CUDA-Fähigkeiten ansehen und in der Praxis die Rechenfähigkeiten des G92-Grafikchips der GeForce 8800 GT-Grafikkarte evaluieren.
Sehen wir uns jedoch zunächst einige Nuancen bei der Durchführung von Berechnungen mit GPUs an. Ihr Hauptvorteil besteht darin, dass der Grafikchip anfänglich dafür ausgelegt ist, mehrere Threads auszuführen, und jeder Kern einer herkömmlichen CPU einen Strom von sequentiellen Anweisungen ausführt. Jede moderne GPU ist ein Multiprozessor, der aus mehreren Compute-Clustern mit jeweils vielen ALUs besteht. Der leistungsstärkste moderne GT200-Chip besteht aus 10 solcher Cluster mit jeweils 24 Stream-Prozessoren. Die getestete Grafikkarte GeForce 8800 GT auf Basis des G92-Chips verfügt über sieben große Recheneinheiten mit jeweils 16 Stream-Prozessoren. CPUs verwenden SIMD-Blöcke SSE für die Vektorberechnung (einzelner Befehl mehrere Daten - ein Befehl wird für mehrere Daten ausgeführt), was eine Datentransformation in 4 Vektoren erfordert. Die GPU verarbeitet Threads skalar, d.h. eine Anweisung wird auf mehrere Threads angewendet (SIMT - Single Instruction Multiple Threads). Dies erspart Entwicklern die Konvertierung von Daten in Vektoren und ermöglicht eine beliebige Verzweigung in Streams. Jede GPU-Recheneinheit hat direkten Speicherzugriff. Und die Bandbreite des Videospeichers ist aufgrund der Verwendung mehrerer separater Speichercontroller (auf dem Top-End-G200 gibt es 8 64-Bit-Kanäle) und der hohen Betriebsfrequenzen höher.
Generell erweisen sich GPUs bei bestimmten Aufgaben bei der Arbeit mit großen Datenmengen als viel schneller als die CPU. Unten sehen Sie eine Illustration dieser Aussage:
Das Diagramm zeigt die Wachstumsdynamik der CPU- und GPU-Leistung seit 2003. Diese Daten werden von NVIDIA gerne als Werbung in ihren Dokumenten zitiert, aber sie sind nur eine theoretische Berechnung und tatsächlich kann die Lücke natürlich viel kleiner ausfallen.
Aber wie dem auch sei, es gibt ein riesiges Potenzial an GPUs, die verwendet werden können und die einen spezifischen Ansatz in der Softwareentwicklung erfordern. All dies ist in der CUDA Hardware- und Softwareumgebung implementiert, die aus mehreren Softwareschichten besteht – der High-Level CUDA Runtime API und der Low-Level CUDA Driver API.

CUDA verwendet die Standardsprache C für die Programmierung, was einer der Hauptvorteile für Entwickler ist. CUDA enthält zunächst die Bibliotheken BLAS (Basic Linear Algebra Software Package) und FFT (Fourier-Transformationsberechnung). Außerdem verfügt CUDA über die Fähigkeit, mit den Grafik-APIs OpenGL oder DirectX zu interagieren, die Entwicklungsfähigkeit auf niedrigem Niveau, die sich durch eine optimierte Verteilung der Datenströme zwischen CPU und GPU auszeichnet. CUDA-Berechnungen werden gleichzeitig mit grafischen durchgeführt, im Gegensatz zur ähnlichen AMD-Plattform, bei der für Berechnungen auf der GPU in der Regel eine spezielle virtuelle Maschine gestartet wird. Aber ein solches "Zusammenleben" ist mit Fehlern behaftet, wenn eine große Last der Grafik-API erzeugt wird, während gleichzeitig CUDA läuft - schließlich haben Grafikoperationen immer noch eine höhere Priorität. Die Plattform ist kompatibel mit 32- und 64-Bit-Betriebssystemen Windows XP, Windows Vista, MacOS X und verschiedenen Linux-Versionen... Die Plattform ist offen und auf der Site können Sie neben speziellen Treibern für die Grafikkarte auch die Softwarepakete CUDA Toolkit und CUDA Developer SDK herunterladen, einschließlich Compiler, Debugger, Standardbibliotheken und Dokumentation.
Was die praktische Umsetzung von CUDA angeht, wurde diese Technologie lange Zeit nur für hochspezialisierte mathematische Berechnungen im Bereich der Teilchenphysik, Astrophysik, Medizin oder der Vorhersage von Veränderungen auf dem Finanzmarkt usw. verwendet. Doch diese Technologie rückt nach und nach dem Normalverbraucher näher, insbesondere gibt es spezielle Plug-Ins für Photoshop, die die Rechenleistung der GPU nutzen können. Auf einer speziellen Seite können Sie die gesamte Liste der Programme anzeigen, die NVIDIA CUDA-Funktionen verwenden.
Als Praxistest der neuen Technologie auf der MSI NX8800GT-T2D256E-OC Grafikkarte verwenden wir das Programm TMPGEnc. Dieses Produkt ist ein kommerzielles Produkt (die Vollversion kostet 100 US-Dollar), aber es wird mit MSI-Grafikkarten als Bonus in einer Testversion für einen Zeitraum von 30 Tagen geliefert. Herunterladen diese Version es ist von der Entwicklerseite möglich, aber um TMPGEnc 4.0 XPress MSI Special Edition zu installieren, benötigen Sie eine Original-Treiberdiskette von der MSI-Karte - das Programm kann ohne sie nicht installiert werden.
Um die umfassendsten Informationen über die Rechenfähigkeiten in CUDA anzuzeigen und mit anderen Videoadaptern zu vergleichen, können Sie das spezielle Dienstprogramm CUDA-Z verwenden. Hier sind die Informationen zu unserer GeForce 8800GT-Grafikkarte:
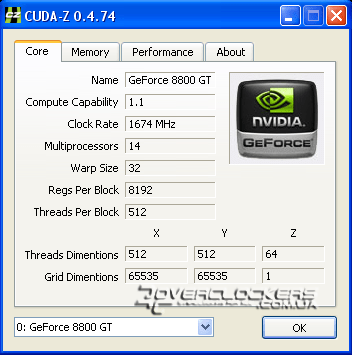


Im Vergleich zu den Referenzmodellen arbeitet unser Sample mit höheren Frequenzen: Die Rasterdomäne ist 63 MHz höher als nominell, die Shader-Einheiten sind um 174 MHz schneller und der Speicher ist 100 MHz höher.
Wir vergleichen die Konvertierungsgeschwindigkeit desselben HD-Videos bei der Berechnung nur mit der CPU und mit zusätzlicher Aktivierung von CUDA im TMPGEnc-Programm in der folgenden Konfiguration:
- Prozessor: Pentium Dual-Core E5200 2,5 GHz;
- Hauptplatine: Gigabyte P35-S3;
- Speicher: 2x1GB GoodRam PC6400 (5-5-5-18-2T)
- Grafikkarte: MSI NX8800GT-T2D256E-OC;
- Festplatte: 320 GB WD3200AAKS;
- Stromversorgung: CoolerMaster eXtreme Power 500-PCAP;
- Betriebssystem: Windows XP SP2;
- TMPGEnc 4.0 XPress 4.6.3.268;
- Grafikkartentreiber: ForceWare 180.60.

Die Kodierung wurde mit dem DivX 6.8.4-Codec durchgeführt. In den Qualitätseinstellungen dieses Codecs werden standardmäßig alle Werte belassen, Multithreading ist aktiviert.

Die TMPGEnc-Multithreading-Unterstützung ist zunächst auf der Registerkarte CPU / GPU-Einstellungen aktiviert. CUDA wird ebenfalls im selben Abschnitt aktiviert.

Wie Sie im obigen Screenshot sehen können, ist die Filterverarbeitung mit CUDA aktiviert und der Hardware-Videodecoder ist nicht aktiviert. Die Dokumentation zum Programm warnt davor, dass die Aktivierung des letzten Parameters zu einer Verlängerung der Verarbeitungszeit der Datei führt.
Basierend auf den Ergebnissen der durchgeführten Tests wurden die folgenden Daten erhalten:

Mit einem 4-GHz-Prozessor mit aktiviertem CUDA haben wir nur wenige Sekunden (oder 2 %) gewonnen, was nicht besonders beeindruckend ist. Bei einer niedrigeren Frequenz können Sie durch die Aktivierung dieser Technologie jedoch etwa 13% der Zeit sparen, was sich bei der Verarbeitung großer Dateien deutlich bemerkbar macht. Dennoch sind die Ergebnisse nicht so beeindruckend wie erwartet.
Das Programm TMPGEnc hat einen Indikator für CPU- und CUDA-Last, in dieser Testkonfiguration zeigte es die CPU-Last um etwa 20 % und den Grafikkern um die restlichen 80 % an. Als Ergebnis haben wir die gleichen 100% wie bei der Konvertierung ohne CUDA und es gibt möglicherweise überhaupt keinen Zeitunterschied (aber er existiert immer noch). Auch die geringe Speichergröße von 256 MB ist kein limitierender Faktor. Den Messwerten von RivaTuner nach zu urteilen, wurden während der Arbeit nicht mehr als 154 MB Videospeicher verwendet.

Schlussfolgerungen
Das TMPGEnc-Programm gehört zu denen, die die CUDA-Technologie in die breite Masse bringen. Die Verwendung der GPU in diesem Programm ermöglicht es Ihnen, den Videoverarbeitungsprozess zu beschleunigen und den Zentralprozessor erheblich zu entlasten, sodass der Benutzer gleichzeitig andere Aufgaben bequem erledigen kann. In unserem konkreten Beispiel hat die GeForce 8800GT 256 MB Grafikkarte das Timing beim Konvertieren von Videos auf Basis des übertakteten Pentium Dual-Core E5200 Prozessors leicht verbessert. Es ist jedoch deutlich zu erkennen, dass mit abnehmender Frequenz der Gewinn durch die Aktivierung von CUDA zunimmt; bei schwachen Prozessoren wird der Gewinn durch die Verwendung viel größer sein. Vor dem Hintergrund einer solchen Abhängigkeit ist es durchaus logisch anzunehmen, dass sich die Ergebnisse eines Systems mit CUDA auch bei einer Erhöhung der Last (z. B. Verwendung einer sehr großen Anzahl zusätzlicher Videofilter) durch ein signifikanteres Delta des Unterschieds in der Zeit, die für den Codierprozess aufgewendet wird. Vergessen Sie auch nicht, dass der G92 derzeit nicht der leistungsstärkste Chip ist und modernere Grafikkarten in solchen Anwendungen eine viel höhere Leistung bieten. Während des Betriebs der Anwendung wird die GPU jedoch nicht vollständig geladen und die Lastverteilung hängt wahrscheinlich von jeder Konfiguration separat ab, nämlich vom Prozessor / Grafikkarten-Bundle, was zu einem größeren (oder kleineren) ) als Prozentsatz der CUDA-Aktivierung erhöhen. Für diejenigen, die mit großen Videodatenmengen arbeiten, spart diese Technologie in jedem Fall noch erheblich Zeit.
CUDA hat zwar noch keine große Popularität erlangt, die Qualität der Software, die mit dieser Technologie arbeitet, muss verbessert werden. Diese Technologie funktionierte im von uns getesteten Programm TMPGEnc 4.0 XPress nicht immer. Ein und dasselbe Video konnte mehrmals umkodiert werden, und beim nächsten Start war die CUDA-Last dann plötzlich bereits 0%. Und dieses Phänomen war auf ganz anderen Betriebssystemen völlig zufällig. Auch weigerte sich das getestete Programm, CUDA bei der Kodierung in das XviD-Format zu verwenden, aber es gab keine Probleme mit dem beliebten DivX-Codec.
Infolgedessen ermöglicht die CUDA-Technologie bisher nur bei bestimmten Aufgaben eine deutliche Leistungssteigerung von Personalcomputern. Aber der Anwendungsbereich dieser Technologie wird sich erweitern, und der Prozess der Erhöhung der Anzahl der Kerne in herkömmlichen Prozessoren zeigt die wachsende Nachfrage nach parallelem Multithread-Computing in modernen Softwareanwendungen. Nicht umsonst sind in letzter Zeit alle Branchenführer mit der Idee in Brand geraten, CPU und GPU in einer einheitlichen Architektur zu vereinen (erinnern Sie sich zumindest an die beworbene AMD Fusion). Vielleicht ist CUDA eine der Phasen im Prozess dieser Fusion.
Wir danken folgenden Firmen für die Bereitstellung der Prüfmittel:
Und es wurde entwickelt, um den Hostcode (Haupt-, Steuercode) und Gerätecode (Hardwarecode) (Dateien mit der Erweiterung .cu) in Objektdateien zu übersetzen, die zum Erstellen des endgültigen Programms oder der endgültigen Bibliothek in jeder Programmierumgebung geeignet sind, z NetBeans.
Die CUDA-Architektur verwendet ein Grid-Speichermodell, Cluster-Threading und SIMD-Anweisungen. Anwendbar nicht nur für Hochleistungs-Grafik-Computing, sondern auch für verschiedene wissenschaftliche Computer mit nVidia-Grafikkarten. Wissenschaftler und Forscher verwenden CUDA umfassend in einer Vielzahl von Bereichen, darunter Astrophysik, Computerbiologie und -chemie, Strömungssimulation, elektromagnetische Wechselwirkungen, Computertomographie, seismische Analyse und mehr. CUDA kann sich mit Anwendungen über OpenGL und Direct3D verbinden. CUDA ist eine plattformübergreifende Software für Betriebssysteme wie Linux, Mac OS X und Windows.
Am 22. März 2010 hat nVidia das CUDA Toolkit 3.0 veröffentlicht, das OpenCL-Unterstützung beinhaltet.
Ausrüstung
Die CUDA-Plattform erschien erstmals mit der Veröffentlichung des NVIDIA-G80-Chips der achten Generation auf dem Markt und wurde in allen nachfolgenden Serien von Grafikchips präsent, die in den Beschleunigerfamilien GeForce, Quadro und NVidia Tesla verwendet werden.
Die erste Hardwareserie, die das CUDA SDK unterstützte, das G8x, hatte einen 32-Bit-Vektorprozessor mit einfacher Präzision, der das CUDA SDK als API verwendet (CUDA unterstützt den C-Doppeltyp, aber seine Präzision wurde jetzt auf 32-Bit herabgestuft Gleitkomma). Spätere GT200-Prozessoren unterstützen 64-Bit-Präzision (nur für SFU), aber die Leistung ist deutlich schlechter als für 32-Bit-Präzision (aufgrund der Tatsache, dass es für jeden Stream-Multiprozessor nur zwei SFUs gibt und es acht Skalarprozessoren gibt) . Die GPU organisiert Hardware-Multithreading, wodurch alle GPU-Ressourcen genutzt werden können. Damit eröffnet sich die Perspektive, die Funktionen eines physikalischen Beschleunigers auf einen Grafikbeschleuniger zu verlagern (Beispiel für die Implementierung ist nVidia PhysX). Außerdem gibt es vielfältige Möglichkeiten, die grafische Ausrüstung eines Computers für komplexe nichtgrafische Berechnungen zu verwenden: zum Beispiel in der Computerbiologie und in anderen Wissenschaftszweigen.
Vorteile
Im Vergleich zu herkömmlichen Computern allgemeiner Zweck Durch die Fähigkeiten der Grafik-API bietet die CUDA-Architektur in diesem Bereich folgende Vorteile:
Einschränkungen
- Alle auf dem Gerät ausgeführten Funktionen unterstützen keine Rekursion (in CUDA Toolkit 3.1 unterstützt es Zeiger und Rekursion) und haben einige andere Einschränkungen
Unterstützte GPUs und Grafikbeschleuniger
Eine Liste der Geräte des Geräteherstellers Nvidia mit der erklärten vollständigen Unterstützung der CUDA-Technologie finden Sie auf der offiziellen Nvidia-Website: CUDA-Enabled GPU Products.
Tatsächlich unterstützen auf dem heutigen PC-Hardwaremarkt die folgenden Peripheriegeräte die CUDA-Technologie:
| Spezifikationsversion | GPU | Grafikkarten |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX/Ultra, 9400GT, 9600GT, 9800GT, Tesla C/D/S870, FX4/5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS / GT, 8600GT / GTS, 8800GT / GTS, 9600 GSO, 9800GTX / GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18/3700, 4700x2, 1xxM, 32 / 370M, 3/5 / 770M, 16/17/27/28/36/37 / 3800M, NVS420 / 50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370 / 380M, NVS 2 / 3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C / M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S / M2050 / 70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GeForce (GF110) GTX 560 TI 448, GTX570, GTX580, GTX590 |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce 610M, GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650 Ti, GTX 650, GT 640, GeForce GTX 680MX, GeForce GTX 680M, GeForce GTX 675MX, GeForce GTX 670MX, GTX 660M, GeForce GT 650M, GeForce GT 645M, GeForce GT 640M |
| 3.5 | GK110 |
|
|
|
|
|
- Mit den Modellen Tesla C1060, Tesla S1070, Tesla C2050 / C2070, Tesla M2050 / M2070, Tesla S2050 können Sie Berechnungen auf einer GPU mit doppelter Genauigkeit durchführen.
Funktionen und Spezifikationen verschiedener Versionen
| Funktionsunterstützung (nicht aufgeführte Funktionen sind für alle Rechenfunktionen unterstützt) |
Rechenfähigkeit (Version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
32-Bit-Wörter im globalen Speicher |
Nein | Jawohl | |||
Gleitkommawerte im globalen Speicher |
|||||
| Ganzzahlige atomare Funktionen arbeiten auf 32-Bit-Wörter im Shared Memory |
Nein | Jawohl | |||
| atomicExch() arbeitet mit 32-Bit Gleitkommawerte im Shared Memory |
|||||
| Ganzzahlige atomare Funktionen arbeiten auf 64-Bit-Wörter im globalen Speicher |
|||||
| Warp-Abstimmungsfunktionen | |||||
| Gleitkommaoperationen mit doppelter Genauigkeit | Nein | Jawohl | |||
| Atomare Funktionen, die auf 64-Bit arbeiten ganzzahlige Werte im Shared Memory |
Nein | Jawohl | |||
| Fließkomma-Atomaddition auf 32-Bit-Wörter im globalen und gemeinsamen Speicher |
|||||
| _wahl () | |||||
| _threadfence_system () | |||||
| _syncthreads_count(), _syncthreads_und (), _syncthreads_oder () |
|||||
| Oberflächenfunktionen | |||||
| 3D-Raster des Gewindeblocks | |||||
| Technische Spezifikationen | Rechenfähigkeit (Version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
| Maximale Dimensionalität des Rasters von Gewindeblöcken | 2 | 3 | |||
| Maximale x-, y- oder z-Dimension eines Rasters von Gewindeblöcken | 65535 | ||||
| Maximale Dimensionalität des Gewindeblocks | 3 | ||||
| Maximales x- oder y-Maß eines Blocks | 512 | 1024 | |||
| Maximales Z-Maß eines Blocks | 64 | ||||
| Maximale Anzahl von Threads pro Block | 512 | 1024 | |||
| Kettgröße | 32 | ||||
| Maximale Anzahl residenter Blöcke pro Multiprozessor | 8 | ||||
| Maximale Anzahl residenter Warps pro Multiprozessor | 24 | 32 | 48 | ||
| Maximale Anzahl residenter Threads pro Multiprozessor | 768 | 1024 | 1536 | ||
| Anzahl 32-Bit-Register pro Multiprozessor | 8 Tausend | 16 K | 32 K | ||
| Maximale Menge an gemeinsam genutztem Speicher pro Multiprozessor | 16 KB | 48 KB | |||
| Anzahl der gemeinsam genutzten Speicherbänke | 16 | 32 | |||
| Menge des lokalen Speichers pro Thread | 16 KB | 512 KB | |||
| Konstante Speichergröße | 64 KB | ||||
| Cache-Working-Set pro Multiprozessor für konstanten Speicher | 8 KB | ||||
| Cache-Working-Set pro Multiprozessor für Texturspeicher | Geräteabhängig, zwischen 6 KB und 8 KB | ||||
| Maximale Breite für 1D-Textur |
8192 | 32768 | |||
| Maximale Breite für 1D-Textur Referenz an lineares Gedächtnis gebunden |
2 27 | ||||
| Maximale Breite und Anzahl der Schichten für eine 1D geschichtete Texturreferenz |
8192 x 512 | 16384 x 2048 | |||
| Maximale Breite und Höhe für 2D Texturreferenz gebunden an linearer Speicher oder ein CUDA-Array |
65536 x 32768 | 65536 x 65535 | |||
| Maximale Breite, Höhe und Anzahl von Ebenen für eine 2D-Ebenen-Texturreferenz |
8192 x 8192 x 512 Zoll | 16384 x 16384 x 2048 | |||
| Maximale Breite, Höhe und Tiefe für eine an linear gebundene 3D-Texturreferenz Speicher oder ein CUDA-Array |
2048 x 2048 x 2048 | ||||
| Maximale Anzahl von Texturen, die kann an einen Kernel gebunden werden |
128 | ||||
| Maximale Breite für eine 1D-Oberfläche Referenz, die an ein CUDA-Array gebunden ist |
Nicht unterstützt |
8192 | |||
| Maximale Breite und Höhe für ein 2D Oberflächenreferenz, die an ein CUDA-Array gebunden ist |
8192 x 8192 | ||||
| Maximale Anzahl von Oberflächen, die kann an einen Kernel gebunden werden |
8 | ||||
| Maximale Anzahl von Anweisungen pro Kernel |
2 Millionen | ||||
Beispiel
CudaArray * cu_array; Textur< float , 2 >Text; // Array zuordnen cudaMalloc (& cu_array, cudaCreateChannelDesc< float>(), Breite Höhe); // Bilddaten in das Array kopieren cudaMemcpy (cu_array, image, width * height, cudaMemcpyHostToDevice); // Binden Sie das Array an die Textur cudaBindTexture (tex, cu_array); // Kernel dim3 blockDim ausführen (16, 16, 1); dim3 gridDim (Breite / blockDim.x, Höhe / blockDim.y, 1); Kernel<<< gridDim, blockDim, 0 >>> (d_odata, Breite, Höhe); cudaUnbindTexture (tex); __global__ void kernel (float * odata, int height, int width) (unsigned int x = blockIdx.x * blockDim.x + threadIdx.x; unsigned int y = blockIdx.y * blockDim.y + threadIdx.y; float c = texfetch (tex, x, y); odata [y * width + x] = c;)
pycuda.driver als drv importieren import numpy drv.init () dev = drv.Device (0) ctx = dev.make_context () mod = drv.SourceModule ( "" "__global__ void multiply_them (float * dest, float * a, float * b) (const int i = threadIdx.x; dest [i] = a [i] * b [i];)" "") multiply_them = mod.get_function ("multiply_them") a = numpy.random .randn (400) .astype (numpy.float32) b = numpy.random .randn (400) .astype (numpy.float32) dest = numpy.zeros_like (a) multiply_them (drv.Out (dest), drv.In (a), drv.In (b), block = (400, 1, 1)) print dest-a * b
CUDA als Fach an Universitäten
Seit Dezember 2009 wird das CUDA-Programmiermodell an 269 Universitäten weltweit gelehrt. In Russland werden CUDA-Schulungen an der Polytechnischen Universität St. Petersburg, der nach V.I. PG Demidov, Moskau, Nischni Nowgorod, St. Petersburg, Twer, Kasan, Nowosibirsk, Staatliche Technische Universität Nowosibirsk Omsk und Staatliche Universitäten Perm, Internationale Universität der Natur der Gesellschaft und des Menschen "Dubna", Staatliche Universität für Energietechnik Ivanovo, Staatliche Universität Belgorod, MSTU sie. Bauman, RKhTU sie. Mendelejew, Interregionales Supercomputerzentrum RAS,. Darüber hinaus wurde im Dezember 2009 bekannt gegeben, dass das erste russische Wissenschafts- und Bildungszentrum "Parallel Computing" in der Stadt Dubna ins Leben gerufen wurde, zu dessen Aufgaben Schulungen und Beratungen zur Lösung komplexer Rechenprobleme auf der GPU gehören.
In der Ukraine werden CUDA-Kurse am Kiewer Institut für Systemanalyse gelehrt.
Links
Offizielle Ressourcen
- CUDA Zone (Russisch) - die offizielle Seite von CUDA
- CUDA GPU Computing - Offizielle Webforen zum Thema CUDA Computing
Inoffizielle Ressourcen
Toms Hardware- Dmitri Tschekanow. nVidia CUDA: GPU-Computing oder CPU-Tod? ... Tom "s Hardware (22. Juni 2008). Archiviert
- Dmitri Tschekanow. nVidia CUDA: GPU-Benchmarks für den Mainstream-Markt. Tom "s Hardware (19. Mai 2009). Archiviert am 4. März 2012. Abgerufen am 19. Mai 2009.
- Alexey Berillo. NVIDIA CUDA - Nicht-Grafik-Computing auf GPUs. Teil 1 . iXBT.com (23. September 2008). Archiviert vom Original am 4. März 2012. Abgerufen am 20. Januar 2009.
- Alexey Berillo. NVIDIA CUDA - Nicht-Grafik-Computing auf GPUs. Teil 2 . iXBT.com (22. Oktober 2008). - Beispiele für die NVIDIA CUDA-Implementierung. Archiviert vom Original am 4. März 2012. Abgerufen am 20. Januar 2009.
- Boreskow Alexej Wiktorowitsch. CUDA-Grundlagen (20. Januar 2009). Archiviert vom Original am 4. März 2012. Abgerufen am 20. Januar 2009.
- Wladimir Frolow. Einführung in die CUDA-Technologie. Netzwerkprotokoll « Computergrafik und Multimedia “(19. Dezember 2008). Archiviert vom Original am 4. März 2012. Abgerufen am 28. Oktober 2009.
- Igor Oskolkow. NVIDIA CUDA ist die erschwingliche Eintrittskarte in die Welt des Big Computing. Computerra (30. April 2009). Abgerufen am 3. Mai 2009.
- Wladimir Frolow. Einführung in die CUDA-Technologie (1. August 2009). Archiviert vom Original am 4. März 2012. Abgerufen am 3. April 2010.
- GPGPU.ru. Verwenden von Grafikkarten für Computer
- ... Zentrum für paralleles Rechnen
Notizen (Bearbeiten)
siehe auch
| Nvidia | ||||||||
|---|---|---|---|---|---|---|---|---|
| Grafik Prozessoren |
| |||||||
Nach Darwins Evolutionstheorie ist der erste Menschenaffe (wenn
um genau zu sein - Homo-Vorgänger, menschlicher Vorgänger) später gedreht
in uns. Multi-Tonnen-Rechenzentren mit tausend oder mehr Funkröhren,
ganze Räume besetzten, wurden durch Halb-Kilogramm-Laptops ersetzt, die übrigens
wird dem ersten in der Leistung nicht nachgeben. Vorsintflutliche Schreibmaschinen sind geworden
beim Drucken von allem und auf allem (auch auf dem menschlichen Körper)
multifunktionale Geräte. Prozessorgiganten haben sich plötzlich entschlossen, zuzumauern
Grafikkern in "Stein". Und Grafikkarten begannen nicht nur ein Bild mit zu zeigen
akzeptable FPS- und Grafikqualität, sondern führen auch alle möglichen Berechnungen durch. Jawohl
wie produziert! Über die Technologie des Multithreaded Computing mittels GPU und wird diskutiert.
Warum GPU?
Ich frage mich, warum sie beschlossen haben, die gesamte Rechenleistung auf die Grafik zu verlagern
Adapter? Wie Sie sehen, sind Prozessoren immer noch in Mode und es ist unwahrscheinlich, dass sie ihre Wärme aufgeben
Platz. Aber die GPU hat neben dem Joker und den Ärmeln ein paar Trümpfe im Ärmel.
genug. Der moderne Zentralprozessor ist geschärft, um das Maximum zu erreichen
Leistung bei der Verarbeitung von Integer-Daten und Floating-Daten
Komma, ohne sich um die parallele Verarbeitung von Informationen zu kümmern. Gleichzeitig
Mit der Architektur der Grafikkarte können Sie schnell und einfach "parallelisieren"
Datenverarbeitung. Zum einen werden Polygone gezählt (aufgrund des 3D-Förderers),
auf der anderen Seite die Pixeltexturverarbeitung. Man sieht, dass es ein "gut koordiniertes"
Aufschlüsselung "Laden im Kern der Karte. Außerdem funktionieren der Speicher und der Videoprozessor
optimaler als die Kombination "RAM-Cache-Prozessor". Der Moment der Dateneinheit
in der Grafikkarte beginnt die Verarbeitung von einem GPU-Stream-Prozessor, einem anderen
eine Einheit wird parallel in eine andere geladen und ist im Prinzip einfach zu erreichen
GPU-Last vergleichbar mit der Busbandbreite,
dafür muss die Beschickung von Förderern jedoch gleichmäßig erfolgen, ohne
jede bedingte Verzweigung und Verzweigung. Der Zentralprozessor ist aufgrund seiner
Universalität erfordert einen Cache voller
Information.
Experten haben über die Arbeit von GPUs beim parallelen Computing nachgedacht und
Mathematik und leitete die Theorie ab, dass viele wissenschaftliche Berechnungen in vielerlei Hinsicht ähnlich sind wie
Verarbeitung von 3D-Grafiken. Viele Experten glauben, dass ein grundlegender Faktor in
Entwicklung GPGPU (Allgemeine Berechnung auf GPU - universell
Berechnungen mittels einer Grafikkarte) war die Entstehung des Brook-GPU-Projekts im Jahr 2003.
Die Macher des Projekts von der Stanford University hatten eine schwierige Aufgabe zu lösen
Problem: Hard- und Software zwingen die Grafikkarte zur Produktion
vielseitige Berechnungen. Und sie haben es geschafft. Mit der generischen C-Sprache,
Amerikanische Wissenschaftler zwangen die GPU, wie ein Prozessor zu arbeiten, angepasst an
Parallelverarbeitung. Nach Brook erschienen eine Reihe von VGA-Projekten,
wie Accelerator-Bibliothek, Brahma-Bibliothek, System
Metaprogrammierung GPU ++ und andere.
CUDA!
Die Vorahnung der Entwicklungsperspektiven gemacht AMD und NVIDIA
klammert sich wie ein Pitbull an die Brook-GPU. Wenn wir die Marketingrichtlinie auslassen, dann
Wenn man alles richtig umgesetzt hat, kann man nicht nur im Grafikbereich Fuß fassen
Markt, sondern auch im Computing (siehe spezielle Computerkarten und
Server Tesla mit Hunderten von Multiprozessoren), die die üblichen CPUs verdrängen.
Natürlich zerstreuten sich die "FPS-Meister" am Stolperstein, jeder auf seine Weise.
Weg, aber das Grundprinzip ist unverändert geblieben - Berechnungen anzustellen
GPU-Tools. Und nun schauen wir uns die Technik von "grün" genauer an - CUDA
(Compute Unified Device Architecture).
Die Aufgabe unserer "Heldin" besteht darin, eine API bereitzustellen, und zwar zwei gleichzeitig.
Die erste ist die CUDA Runtime auf hoher Ebene, bei der es sich um Funktionen handelt, die
werden in einfachere Ebenen unterteilt und an die untere API - CUDA-Treiber - weitergegeben. So
dass der Ausdruck „hochgradig“ auf einen Dehnungsprozess zutrifft. Das ganze Salz ist
es ist im Treiber und Bibliotheken, freundlicherweise erstellt von
Entwickler NVIDIA: CUBLAS (Werkzeuge für mathematische Berechnungen) und
FFT (Berechnung mittels Fourier-Algorithmus). Kommen wir zur Praxis
Teile des Materials.
CUDA-Terminologie
NVIDIA arbeitet mit sehr eigenartigen Definitionen für die CUDA-API. Sie
sich von den Definitionen unterscheiden, die für die Arbeit mit dem Zentralprozessor verwendet werden.
Gewinde- der zu verarbeitende Datensatz (nicht
erfordert viele Verarbeitungsressourcen).
Kette- eine Gruppe von 32 Streams. Es werden nur Daten verarbeitet
Warps, daher ist Warp die minimale Datenmenge.
Block- eine Reihe von Streams (von 64 bis 512) oder eine Reihe
Kettfäden (von 2 bis 16).
Netz Ist eine Sammlung von Blöcken. Diese Datentrennung
dient ausschließlich der Leistungssteigerung. Also, wenn die Zahl
Multiprozessoren groß ist, werden die Blöcke parallel ausgeführt. Wenn mit
die Karte hatte Pech (die Entwickler empfehlen die Verwendung von
Adapter nicht niedriger als das Niveau der GeForce 8800 GTS 320 MB ist), dann werden die Datenblöcke verarbeitet
konsequent.
Auch NVIDIA führt Konzepte wie Kernel, Gastgeber
und Gerät.
Wir arbeiten!
Um vollständig mit CUDA zu arbeiten, benötigen Sie:
1. Kennen Sie die Struktur von GPU-Shader-Kernen als Essenz der Programmierung
besteht darin, die Last gleichmäßig zwischen ihnen zu verteilen.
2. in der C-Umgebung programmieren können, unter Berücksichtigung einiger Aspekte.
Entwickler NVIDIA enthüllte das "Innere" der Grafikkarte mehrere
anders, als wir es gewohnt sind zu sehen. Also muss man wohl oder übel alles studieren
Feinheiten der Architektur. Analysieren wir die Struktur des "Stein" G80 des legendären GeForce 8800
GTX.
Der Shader-Kern besteht aus acht TPC (Texture Processor Cluster)-Clustern
Texturprozessoren (zum Beispiel GeForce GTX 280- 15 Kerne, 8800 GTS
es gibt sechs davon, 8600
- vier usw.). Diese bestehen wiederum aus zwei
Streaming-Multiprozessoren (im Folgenden als SM bezeichnet). SM (es gibt
16) besteht aus einem Frontend (löst das Problem des Lesens und Dekodierens von Anweisungen) und
Back-End-Pipelines (endgültige Ausgabe von Befehlen) sowie acht skalare SP (Shader
Prozessor) und zwei SFUs (Super Functional Units). Für jede Maßnahme (eine
Zeit) wählt das Frontend den Warp aus und verarbeitet ihn. An alle Ströme des Warp
(denken Sie daran, es gibt 32 davon) verarbeitet, dauert es 32/8 = 4 Zyklen am Ende der Pipeline.
Jeder Multiprozessor verfügt über einen sogenannten Shared Memory.
Seine Größe beträgt 16 Kilobyte und bietet dem Programmierer völlige Freiheit.
Handlung. Verteilen Sie, wie Sie wollen :). Shared Memory bietet Thread-Kommunikation in
ein Block und ist nicht für die Arbeit mit Pixel-Shadern ausgelegt.
Auch SMs können auf DDR zugreifen. Dazu wurden sie auf 8 Kilobyte "genäht"
Cache-Speicher, der das Wichtigste für die Arbeit speichert (z
Konstanten).
Der Multiprozessor hat 8192 Register. Die Anzahl der aktiven Blöcke kann nicht sein
mehr als acht, und die Anzahl der Kettfäden beträgt nicht mehr als 768/32 = 24. Daraus ist ersichtlich, dass G80
kann maximal 32 * 16 * 24 = 12288 Threads pro Zeiteinheit verarbeiten. Es ist unmöglich, nicht
Berücksichtigen Sie diese Zahlen bei der zukünftigen Optimierung des Programms (auf einer Pfanne)
- Blockgröße, andererseits - die Anzahl der Threads). Das Gleichgewicht der Parameter kann spielen
daher eine wichtige Rolle in der Zukunft NVIDIA empfiehlt die Verwendung von Blöcken
mit 128 oder 256 Fäden. Ein Block von 512 Threads ist wirkungslos, da er
erhöhte Verzögerungen. In Anbetracht aller Feinheiten der Struktur der GPU der Grafikkarte plus
gute Programmierkenntnisse, können Sie ein sehr produktives
Werkzeug für paralleles Rechnen. Apropos Programmieren...
Programmierung
Für "Kreativität" zusammen mit CUDA brauchst du GeForce-Grafikkarte nicht niedriger
achte serie... MIT
Auf der offiziellen Website müssen Sie drei Softwarepakete herunterladen: einen Treiber mit
CUDA-Unterstützung (für jedes Betriebssystem - sein eigenes), direkt das CUDA SDK-Paket (das zweite
beta) und zusätzliche Bibliotheken (CUDA-Toolkit). Technologie unterstützt
Operationssäle Windows-Systeme(XP und Vista), Linux und Mac OS X. Zum Studium I
wählte Vista Ultimate Edition x64 (mit Blick auf die Zukunft werde ich sagen, dass sich das System verhalten hat
Einfach perfekt). Zum Zeitpunkt der Erstellung dieses Artikels war folgendes für die Arbeit relevant
ForceWare-Treiber 177.35. Die verwendete Toolbox war
Borland C ++ 6 Builder Softwarepaket (obwohl jede Umgebung, die mit
Sprache C).
Eine Person, die die Sprache kennt, wird sich leicht an die neue Umgebung gewöhnen. Es dauert nur
merken Sie sich die grundlegenden Parameter. Stichwort _global_ (vor der Funktion platziert)
zeigt an, dass die Funktion zum Kernel gehört. Es wird von der Zentrale aufgerufen
Prozessor, und die ganze Arbeit wird auf der GPU passieren. Der Aufruf an _global_ erfordert mehr
spezifische Details, nämlich Maschenweite, Blockgröße und welcher Kern sein wird
angewandt. Zum Beispiel die Zeile _global_ void saxpy_parallel<<
die Rastergröße und Y die Blockgröße ist, legt diese Parameter fest.
Das _device_-Symbol bedeutet, dass die Funktion vom Grafikkern aufgerufen wird, es ist
werde alle Anweisungen befolgen. Diese Funktion befindet sich im Speicher des Multiprozessors,
Daher ist es unmöglich, seine Adresse zu erhalten. Das Präfix _host_ bedeutet, dass der Aufruf
und Verarbeitung erfolgt nur unter Beteiligung der CPU. Es ist zu beachten, dass _global_ und
_device_ können sich nicht gegenseitig anrufen und können sich nicht selbst aufrufen.
Außerdem bietet die Sprache für CUDA eine Reihe von Funktionen für die Arbeit mit Videospeicher: cudafree
(Speicher freigeben zwischen GDDR und RAM), cudamemcpy und cudamemcpy2D (Kopieren
Speicher zwischen GDDR und RAM) und cudamalloc (Speicherzuweisung).
Alle Programmcodes werden von der CUDA API kompiliert. Zuerst wird genommen
Code, der ausschließlich für die CPU bestimmt ist und exponiert ist
Standardkompilierung und anderer Code für die Grafikkarte,
wird in die Zwischensprache PTX (sehr ähnlich dem Assembler) umgeschrieben für
mögliche Fehler erkennen. Nach all diesen "Tänzen", dem Finale
Übersetzung (Übersetzung) von Befehlen in eine für die GPU / CPU verständliche Sprache.
Studienset
Fast alle Aspekte der Programmierung sind in der dazugehörigen Dokumentation beschrieben
zusammen mit einem Treiber und zwei Anwendungen sowie auf der Entwicklerseite. Größe
der Artikel reicht nicht aus, um sie zu beschreiben (der interessierte Leser sollte anhängen
ein wenig Mühe und studieren Sie das Material selbst).
Der CUDA SDK Browser wurde speziell für Anfänger entwickelt. Jeder kann
Spüren Sie die Kraft des parallelen Rechnens auf Ihrer eigenen Haut ( am besten checken An
Stabilität - Beispielarbeit ohne Artefakte und Abstürze). Die App hat
eine große Anzahl demonstrativer Miniprogramme (61 "Tests"). Jede Erfahrung hat
ausführliche Codedokumentation plus PDFs. Es ist sofort klar, dass die Leute
diejenigen, die mit ihren Kreationen im Browser anwesend sind, leisten ernsthafte Arbeit.
Sie können auch die Geschwindigkeit des Prozessors und der Grafikkarte während der Verarbeitung vergleichen
Daten. Zum Beispiel das Scannen mehrdimensionaler Arrays mit einer Grafikkarte GeForce 8800
GT 512 MB mit einem Block mit 256 Threads ergeben in 0,17109 Millisekunden.
Die Technologie erkennt keine SLI-Tandems. Wenn Sie also ein Duett oder Trio haben,
Schalten Sie die "Pairing"-Funktion vor der Arbeit aus, sonst sieht CUDA nur eine
Gerät. Zweikern AMD Athlon 64 X2(Kernfrequenz 3000 MHz) das gleiche Erlebnis
vergeht in 2,761528 Millisekunden. Es stellt sich heraus, dass der G92 mehr als 16-mal ist
schneller als "Stein" AMD! Wie Sie sehen, ist es weit entfernt von einem extremen System in
Tandem mit den Ungeliebten unter den Massen Betriebssystem zeigt gut
Ergebnisse.
Neben dem Browser gibt es eine Reihe von Programmen, die für die Gesellschaft nützlich sind. Adobe
hat seine Produkte an neue Technologien angepasst. Photoshop CS4 ist jetzt fertig
nutzt zumindest die Ressourcen von Grafikkarten (Sie müssen ein spezielles herunterladen
Plugin). Programme wie Badaboom Media Converter und RapiHD können
Video in das MPEG-2-Format dekodieren. Nicht schlecht für die Tonverarbeitung
Das kostenlose Dienstprogramm Accelero wird es tun. Die Anzahl der auf die CUDA-API zugeschnittenen Software,
wird zweifellos wachsen.
Und zu dieser Zeit ...
In der Zwischenzeit lesen Sie dieses Material, harte Arbeiter aus Verarbeiterangelegenheiten
entwickeln eigene Technologien zur Integration von GPUs in CPUs. Von der Seite AMD alle
verständlich: Sie haben enorme Erfahrung mit ATI.
Die Schaffung von "Mikroentwicklern", Fusion, besteht aus mehreren Kernen unter
Codename Bulldozer und Videochip RV710 (Kong). Ihre Beziehung wird
aufgrund des verbesserten HyperTransport-Busses durchgeführt. Abhängig von
die Anzahl der Kerne und deren Frequenzcharakteristik AMD plant eine vollständige Preisgestaltung
Hierarchie der "Steine". Geplant ist auch die Produktion von Prozessoren für Laptops (Falcon),
und für Multimedia-Gadgets (Bobcat). Darüber hinaus ist es der Einsatz von Technologie
in tragbaren Geräten wird die erste Herausforderung für die Kanadier sein. Mit Entwicklung
Parallel Computing dürfte die Verwendung solcher "Steine" sehr beliebt sein.
Intel etwas im Rückstand mit seinem Larrabee. Produkte AMD,
wenn nichts passiert, erscheint Ende 2009 - früh in den Ladenregalen
2010. Und die Entscheidung des Feindes wird erst nach fast zwei ans Licht kommen
des Jahres.
Larrabee wird eine große Anzahl (lesen Sie Hunderte) von Kernen haben. Am Anfang
es wird Produkte geben, die für 8 - 64 Kerne ausgelegt sind. Sie sind dem Pentium sehr ähnlich, aber
ziemlich überarbeitet. Jeder Kern verfügt über 256 Kilobyte L2-Cache
(er wird mit der Zeit größer). Die Beziehung wird durchgeführt durch
Bidirektionaler 1024-Bit-Ringbus. Intel sagt, dass ihr "Kind" wird
funktioniert hervorragend mit DirectX und Open GL API (für Yabloko), also nein
es ist kein Softwareeingriff erforderlich.
Warum habe ich dir das alles erzählt? Offensichtlich werden Larrabee und Fusion nicht ersetzen
konventionelle, stationäre Prozessoren vom Markt, ebenso wie sie nicht vom Markt verdrängt werden
Grafikkarten. Für Gamer und extreme Liebhaber wird der ultimative Traum bleiben
eine Multi-Core-CPU und ein Tandem aus mehreren Top-End-VGAs. Aber was auch?
Prozessorunternehmen wechseln auf prinzipienbasierte Parallelverarbeitung
ähnlich wie GPGPU, sagt viel aus. Insbesondere, dass solche
Technologie wie CUDA hat eine Daseinsberechtigung und wird es wahrscheinlich auch sein
sehr berühmt.
Kleine Zusammenfassung
Paralleles Rechnen mit einer Grafikkarte ist nur ein gutes Werkzeug
in den Händen eines fleißigen Programmierers. Unwahrscheinliche Prozessoren unter der Führung des Mooreschen Gesetzes
das Ende wird kommen. Unternehmen NVIDIA es ist noch ein langer weg
Werbung für seine API bei den Massen (dasselbe kann über die Idee gesagt werden) ATI / AMD).
Was es wird, wird die Zukunft zeigen. CUDA wird also wiederkommen :).
PS Ich empfehle für Programmieranfänger und Interessierte einen Besuch
die folgenden "virtuellen Einrichtungen":
Offizielle NVIDIA-Website und -Website
GPGPU.com. Alle
bereitgestellte Informationen - auf Englische Sprache, aber danke, dass du wenigstens nicht dabei bist
Chinesisch. Also los! Ich hoffe, der Autor hat dir zumindest ein wenig geholfen
spannende Unternehmungen, CUDA zu lernen!
Seit Jahrzehnten gilt das Mooresche Gesetz, das besagt, dass sich die Anzahl der Transistoren auf einem Chip alle zwei Jahre verdoppelt. Dies war jedoch bereits 1965, und die Idee des physischen Multicores in Prozessoren der Verbraucherklasse begann sich in den letzten 5 Jahren rasant zu entwickeln: 2005 stellte Intel den Pentium D vor und AMD stellte den Athlon X2 vor. Dann ließen sich Anwendungen mit 2 Kernen an den Fingern einer Hand abzählen. Doch die nächste Generation Intel-Prozessoren das machte die Revolution hatte genau 2 physikalische Kerne. Darüber hinaus erschien im Januar 2007 die Quad-Serie, gleichzeitig gab Moore selbst zu, dass sein Gesetz bald nicht mehr gelten würde.
Was ist jetzt? Dual-Core-Prozessoren selbst in Budget-Office-Systemen und 4 physische Kerne wurden in nur 2-3 Jahren zur Norm. Die Frequenz der Prozessoren nimmt nicht zu, aber die Architektur verbessert sich, die Anzahl der physischen und virtuellen Kerne nimmt zu. Die Idee, Videoadapter zu verwenden, die mit Dutzenden oder sogar Hunderten von Rechen-"Blöcken" ausgestattet sind, gibt es jedoch schon lange.
Und obwohl die Aussichten für das Rechnen mit GPUs riesig sind, ist die beliebteste Lösung Nvidia CUDA kostenlos, enthält viel Dokumentation und ist im Allgemeinen sehr einfach zu implementieren, es gibt jedoch nicht viele Anwendungen, die diese Technologie verwenden. Im Grunde handelt es sich um alle Arten von spezialisierten Berechnungen, die dem normalen Benutzer in den meisten Fällen egal sind. Es gibt aber auch Programme für den Massenanwender, über die wir in diesem Artikel sprechen werden.
Zunächst ein wenig über die Technik selbst und womit sie gegessen wird. Weil Beim Schreiben eines Artikels konzentriere ich mich auf einen breiten Leserkreis, dann werde ich versuchen, ihn in einer zugänglichen Sprache ohne komplexe Begriffe und etwas kurz zu erklären.
CUDA(Englisch Compute Unified Device Architecture) ist eine Software- und Hardwarearchitektur, die Berechnungen mit NVIDIA-Grafikprozessoren ermöglicht, die die GPGPU-Technologie (Arbitrary Computing on Video Cards) unterstützen. Die CUDA-Architektur erschien erstmals mit der Veröffentlichung des NVIDIA G80-Chips der achten Generation auf dem Markt und ist in allen nachfolgenden Grafikchipserien enthalten, die in den Beschleunigerfamilien GeForce, Quadro und Tesla verwendet werden. (c) Wikipedia.org
Eingehende Streams werden unabhängig voneinander verarbeitet, d.h. parallel.

Außerdem gibt es eine Unterteilung in 3 Ebenen:

Netz- Ader. Enthält ein ein- / zwei- / dreidimensionales Array von Blöcken.
Block- enthält viele Threads (Thread). Streams verschiedener Blöcke können nicht miteinander interagieren. Warum mussten Sie Blöcke einführen? Jeder Block ist im Wesentlichen für seine eigene Teilaufgabe verantwortlich. Beispielsweise kann ein großes Bild (das eine Matrix ist) in mehrere kleinere Teile (Matrizen) aufgeteilt werden und mit jedem Teil des Bildes parallel arbeiten.
Gewinde- strömen. Threads innerhalb eines Blocks können entweder über gemeinsam genutzten Speicher, der übrigens viel schneller ist als der globale Speicher, oder über Thread-Synchronisierungstools interagieren.
Kette- Dies ist die Vereinigung von interagierenden Threads, für alle modernen GPUs ist Warps Größe 32. Als nächstes kommt halbe Kette, was eine halbe Warp'a ist, da Speicherzugriffe erfolgen normalerweise getrennt für die erste und zweite Hälfte des Warps.
Wie Sie sehen, eignet sich diese Architektur hervorragend zum Parallelisieren von Aufgaben. Und obwohl die Programmierung in der Sprache C mit einigen Einschränkungen erfolgt, ist es in Wirklichkeit nicht so einfach, denn nicht alles lässt sich parallelisieren. Nein, und Standardfunktionen um Zufallszahlen zu generieren (oder zu initialisieren), muss dies alles separat implementiert werden. Und obwohl es genug vorgefertigte Optionen gibt, macht das alles keine Freude. Die Möglichkeit, Rekursion zu verwenden, ist relativ neu.
Aus Gründen der Übersichtlichkeit wurde ein kleines Konsolenprogramm (um den Code zu minimieren) geschrieben, das Operationen mit zwei Arrays vom Typ float ausführt, d.h. mit nicht ganzzahligen Werten. Aus den obigen Gründen wurde die Initialisierung (das Füllen des Arrays mit verschiedenen willkürlichen Werten) von der CPU durchgeführt. Dann wurden 25 verschiedene Operationen mit den entsprechenden Elementen aus jedem Array durchgeführt, Zwischenergebnisse wurden in das dritte Array geschrieben. Die Array-Größe hat sich geändert, die Ergebnisse sind wie folgt:
Insgesamt wurden 4 Tests durchgeführt:
1024 Elemente in jedem Array:

Es ist klar zu erkennen, dass parallele Berechnungen bei einer so kleinen Anzahl von Elementen wenig Sinn machen, da die Berechnungen selbst sind viel schneller als ihre Vorbereitung.
4096 Elemente in jedem Array:

Und jetzt können Sie sehen, dass die Grafikkarte Operationen auf Arrays dreimal schneller ausführt als der Prozessor. Außerdem ist die Vorlaufzeit dieser Test auf der Grafikkarte hat sich nicht erhöht (eine leichte Verkürzung der Zeit kann auf einen Fehler zurückgeführt werden).
Jetzt gibt es 12288 Elemente in jedem Array:

Der Abstand zwischen der Grafikkarte hat sich verdoppelt. Beachten Sie auch hier, dass sich die Ausführungszeit auf der Grafikkarte erhöht hat.
unbedeutend, aber auf dem Prozessor mehr als 3-mal, d.h. proportional zur Komplexität der Aufgabe.
Und der letzte Test - 36864 Elemente in jedem Array:

In diesem Fall erreicht die Beschleunigung beeindruckende Werte – fast 22-mal schneller auf einer Grafikkarte. Und wieder hat sich die Ausführungszeit auf der Grafikkarte und auf dem Prozessor unbedeutend erhöht - das vorgeschriebene 3-fache, was wiederum proportional zur Komplikation der Aufgabe ist.
Wenn Sie die Berechnungen weiter komplizieren, gewinnt die Grafikkarte immer mehr. Obwohl das Beispiel etwas übertrieben ist, zeigt es die Situation im Allgemeinen deutlich. Aber wie oben erwähnt, kann nicht alles parallelisiert werden. Zum Beispiel die Berechnung von pi. Es gibt nur Beispiele, die mit der Monte-Carlo-Methode geschrieben wurden, aber die Genauigkeit der Berechnungen beträgt 7 Dezimalstellen, d.h. regelmäßige Schwimmer. Um die Genauigkeit der Berechnungen zu erhöhen, ist eine lange Arithmetik erforderlich, aber hier treten Probleme auf, tk. es ist sehr, sehr schwierig, effektiv zu implementieren. Im Internet konnte ich keine Beispiele finden, die CUDA verwenden und die Anzahl von Pi auf 1 Million Dezimalstellen berechnen. Es wurden Versuche unternommen, eine solche Anwendung zu schreiben, aber die einfachste und effizienteste Methode zur Berechnung von pi ist der Brent-Salamin-Algorithmus oder die Gauss-Formel. Im bekannten SuperPI wird höchstwahrscheinlich (gemessen an der Arbeitsgeschwindigkeit und der Anzahl der Iterationen) die Gauß-Formel verwendet. Und nach zu urteilen
die Tatsache, dass SuperPI Single-Threaded ist, das Fehlen von Beispielen für CUDA und das Scheitern meiner Versuche, es ist unmöglich, die Berechnung von Pi effektiv zu parallelisieren.
Übrigens können Sie sehen, wie bei der Durchführung von Berechnungen die Belastung der GPU sowie die Speicherzuweisung zunimmt.

Kommen wir nun zu den praktischen Vorteilen von CUDA, nämlich den derzeit vorhandenen Programmen, die diese Technologie... Meistens sind dies alle Arten von Audio- / Video-Konvertern und -Editoren.
Wir haben 3 verschiedene Videodateien zum Testen verwendet:
- * Die Geschichte des Films Avatar - 1920x1080, MPEG4, h.264.
- * Serie "Lie to me" - 1280x720, MPEG4, h.264.
- * Serie "In Philadelphia ist es immer sonnig" - 624x464, xvid.
Der Container und die Größe der ersten beiden Dateien waren mkv und 1,55 GB und die letzte .avi und 272 MB.
Beginnen wir mit einem sehr sensationellen und beliebten Produkt - Badaboom... Die verwendete Version war - 1.2.1.74 ... Die Kosten für das Programm betragen $29.90 .

Die Programmoberfläche ist einfach und intuitiv - links wählen wir die Quelldatei oder den Datenträger und rechts das erforderliche Gerät aus, für das wir codieren. Es gibt auch einen Benutzermodus, in dem Parameter manuell eingestellt werden, und es wurde verwendet.
Betrachten wir zunächst, wie schnell und effizient das Video "in sich selbst" kodiert wird, d.h. bei gleicher Auflösung und ungefähr gleicher Größe. Die Geschwindigkeit wird in fps gemessen und nicht in der verstrichenen Zeit - es ist bequemer, sowohl zu vergleichen als auch zu berechnen, wie viel Video beliebiger Länge komprimiert wird. Weil heute denken wir über die technologie von "grün" nach, dann werden die grafiken angemessen sein -)

Die Encoding-Geschwindigkeit hängt direkt von der Qualität ab, das ist offensichtlich. Es sollte beachtet werden, dass die Lichtauflösung (nennen wir es traditionell - SD) für Badaboom kein Problem darstellt - die Codierungsgeschwindigkeit ist 5,5-mal höher als die ursprüngliche Videobildrate (24 fps). Und selbst ein schweres 1080p-Video wird vom Programm in Echtzeit konvertiert. Es ist zu beachten, dass die Qualität des endgültigen Videos dem Originalvideo sehr nahe kommt, d.h. Codiert Badaboom sehr, sehr hochwertig.
Aber normalerweise wird das Video auf eine niedrigere Auflösung überholt, mal sehen, wie es in diesem Modus aussieht. Da die Auflösung verringert wurde, sank auch die Video-Bitrate. Es waren 9500 kbps für eine 1080p-Ausgabedatei, 4100 kbps für 720p und 2400 kbps für 720x404. Die Auswahl wurde aufgrund eines vernünftigen Verhältnisses von Größe / Qualität getroffen.

Kommentare sind überflüssig. Wenn Sie von 720p auf normale SD-Qualität rippen, dauert es etwa 30 Minuten, um einen 2-stündigen Film zu transkodieren. Gleichzeitig ist die Prozessorlast unbedeutend, Sie können Ihren Geschäften nachgehen, ohne sich unwohl zu fühlen.
Aber was ist, wenn Sie das Video in ein Format für ein mobiles Gerät konvertieren? Wählen Sie dazu das iPhone-Profil (Bitrate 1 Mbit/s, 480x320) aus und schauen Sie sich die Encoding-Geschwindigkeit an:

Muss ich etwas sagen? Ein 2-stündiger Film in normaler iPhone-Qualität wird in weniger als 15 Minuten transkodiert. HD-Qualität ist schwieriger, aber immer noch recht schnell. Die Hauptsache ist, dass die Qualität des ausgegebenen Videomaterials beim Betrachten auf dem Telefondisplay auf einem ziemlich hohen Niveau bleibt.
Im Allgemeinen sind die Eindrücke von Badaboom positiv, die Arbeitsgeschwindigkeit gefällt, die Benutzeroberfläche ist einfach und unkompliziert. Alle Arten von Fehlern frühe Versionen(gebrauchte Beta im Jahr 2008) geheilt. Abgesehen von einer Sache - der Pfad zur Quelldatei sowie zum Ordner, in dem das fertige Video gespeichert ist, sollte keine russischen Buchstaben enthalten. Vor dem Hintergrund der Vorzüge des Programms ist dieser Nachteil jedoch unbedeutend.
Als nächstes haben wir Super LoiLoScope... Für die übliche Version fragen sie 3 280 Rubel und für Touch-Version unterstützend Berührungssteuerung in Windows 7 fragen sie nach 4 440 Rubel... Versuchen wir herauszufinden, warum der Entwickler so viel Geld will und warum der Videoeditor Multitouch-Unterstützung benötigt. Es wurde die neueste Version verwendet - 1.8.3.3 .
Es ist ziemlich schwierig, die Programmoberfläche mit Worten zu beschreiben, daher habe ich mich entschlossen, ein kurzes Video zu drehen. Ich muss gleich sagen, dass, wie alle Videokonverter für CUDA, die GPU-Beschleunigung nur für die Videoausgabe in MPEG4 mit dem Codec h.264 unterstützt wird.
Während des Enkodierens beträgt die Prozessorlast 100 %, was jedoch keine Beschwerden verursacht. Der Browser und andere nicht schwere Anwendungen werden nicht langsamer.
Kommen wir nun zur Leistung. Zunächst einmal ist alles wie bei Badaboom - Videotranskodierung in gleicher Qualität.

Die Ergebnisse sind viel besser als bei Badaboom. Auch die Qualität ist top, den Unterschied zum Original erkennt man nur, wenn man die Rahmen paarweise unter der Lupe vergleicht.

Wow, und hier umgeht LoiloScope Badaboom 2,5-mal. Gleichzeitig kann man problemlos parallel ein anderes Video schneiden und encodieren, Nachrichten lesen und sogar einen Film anschauen, und sogar FullHD lässt sich problemlos abspielen, obwohl die Prozessorlast maximal ist.
Versuchen wir nun, ein Video für ein mobiles Gerät zu erstellen, wir werden das Profil so benennen, wie es in Badaboom - iPhone (480x320, 1 Mbps) genannt wurde:

Es liegt kein Fehler vor. Alles wurde mehrmals überprüft, jedes Mal war das Ergebnis das gleiche. Dies geschieht höchstwahrscheinlich aus dem einfachen Grund, dass die SD-Datei mit einem anderen Codec und in einem anderen Container geschrieben wird. Beim Transkodieren wird das Video zunächst dekodiert, in Matrizen einer bestimmten Größe aufgeteilt und komprimiert. Der bei xvid verwendete ASP-Decoder ist bei der parallelen Dekodierung langsamer als AVC (für h.264). 192 fps sind jedoch 8-mal schneller als die ursprüngliche Videogeschwindigkeit, ein 23-Minuten-Burst wird in weniger als 4 Minuten komprimiert. Die Situation wiederholte sich mit anderen Dateien, die in xvid / DivX komprimiert wurden.
LoiloScope habe nur angenehme Eindrücke von mir hinterlassen - die Benutzeroberfläche ist trotz ihrer Ungewöhnlichkeit bequem und funktional und die Arbeitsgeschwindigkeit ist nicht zu loben. Die relativ schlechte Funktionalität ist etwas frustrierend, aber oft müssen Sie bei einfacher Bearbeitung nur die Farben leicht anpassen, sanfte Übergänge machen, Text überlagern, und LoiloScope leistet hier hervorragende Arbeit. Etwas erschreckend ist auch der Preis - mehr als 100 Dollar für die reguläre Version sind für das Ausland normal, aber solche Zahlen erscheinen uns noch etwas wild. Obwohl ich gestehe, dass ich, wenn ich zum Beispiel oft Heimvideos gedreht und bearbeitet habe, über einen Kauf nachgedacht hätte. Gleichzeitig habe ich übrigens die Möglichkeit überprüft, HD- (bzw.
Kerne CUDA - Symbol skalare Recheneinheiten in Videochips NVidia, mit ... anfangen G 80 (GeForce 8 xxx, Tesla C-D-S870, Fx4/5600 , 360M). Die Chips selbst sind von der Architektur abgeleitet. Übrigens, weil das Unternehmen NVidia so bereitwillig die Entwicklung eigener Prozessoren aufgegriffen Tegra-Serie auch basierend auf RISC die Architektur. Ich habe viel Erfahrung mit diesen Architekturen.
CUDA der Kern enthält einen ein Vektor und ein Skalar Einheiten, die in einem Taktzyklus eine Vektor- und eine Skalaroperation ausführen, die Berechnungen an einen anderen Multiprozessor übertragen oder zur weiteren Verarbeitung. Ein Array von Hunderten und Tausenden solcher Kerne stellt eine beachtliche Rechenleistung dar und kann je nach Anforderung verschiedene Aufgaben übernehmen, wenn eine bestimmte Software dies unterstützt. Anwendung kann variiert werden: Videostream-Dekodierung, 2D / 3D-Grafikbeschleunigung, Cloud-Computing, spezielle mathematische Analysen usw.
Sehr oft vereint professionelle NVidia Tesla-Karten und NVidia Quadro sind das Rückgrat moderner Supercomputer.
CUDA- die Kerne haben seit der Zeit keine wesentlichen Veränderungen erfahren G 80, aber ihre Zahl nimmt zu (zusammen mit anderen Blöcken - ROP, Textureinheiten& etc) und die Effizienz paralleler Interaktionen untereinander (Module werden verbessert Giga-Thread).

Z.B:
GeForce
GTX 460 - 336 CUDA-Kerne
GTX 580 - 512 CUDA-Kerne
8800GTX - 128 CUDA-Kerne
Aus der Anzahl der Stream-Prozessoren ( CUDA) steigt die Leistung bei Shader-Berechnungen fast proportional (bei gleichmäßiger Zunahme der Anzahl anderer Elemente).
Ausgehend vom Chip GK110(NVidia GeForce GTX 680) - CUDA die Kerne haben keine doppelte Frequenz mehr, sondern eine gemeinsame mit allen anderen Blöcken des Chips. Stattdessen wurde ihre Zahl um etwa erhöht drei Mal im Vergleich zur vorherigen Generation G110.